In today’s tutorial, you will learn how to add a sitemap to your Eleventy website.
But what is a sitemap actually?
An XML sitemap is an essential part of helping internet search engines understand your website’s architecture. Sitemaps are also one of the quickest ways to do a bit of search engine optimization.
With a sitemap, you tell the web crawler which pages you can be crawled and add to the indexes of a web search engine. The crawler will learn from this and prioritize the URLss over other undocumented links in the sitemap.
Once the list of URLs is indexed, you should be able to find your pages through search engines like Google, Bing, or Yandex.
We will be creating an XML sitemap for the lifestyle blog series.
However, we don’t want to create all the page entries manually. So let’s create a custom script that can generate the Eleventy sitemap for us!
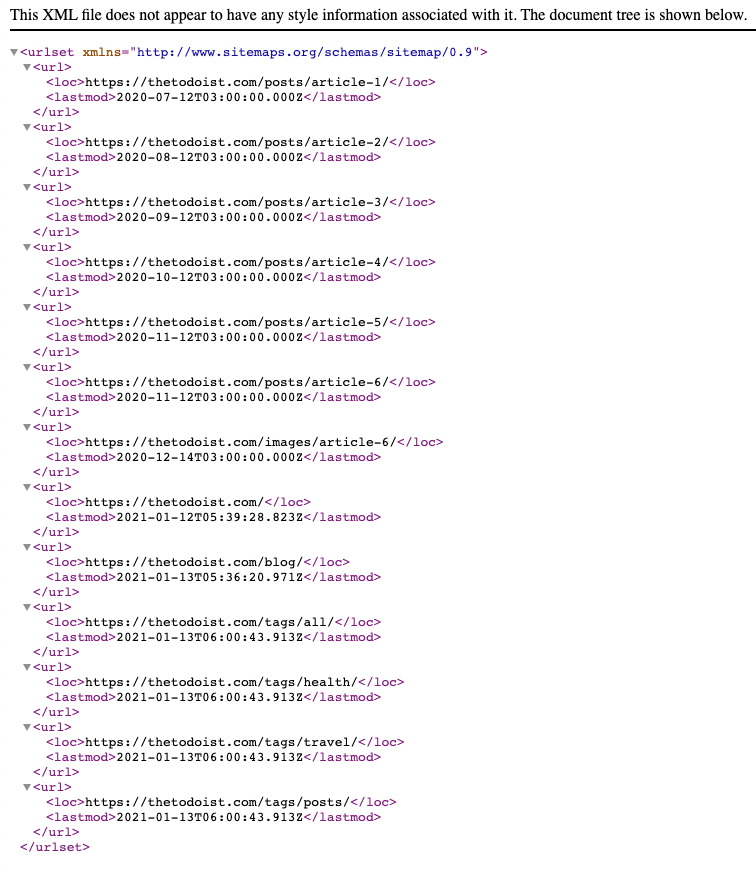
The sitemap.xml will look like this:
Sitemap Structure
First of all, let’s see what a sitemap should look like.
Looking at google’s requested format for XML we get the following result:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com/foo.html</loc>
<lastmod>2018-06-04</lastmod>
</url>
</urlset>
I use an Atom feed for my website, so if you want to learn more about the formats, check out Google’s article on Sitemap formats.
Adding a XML sitemap to an Eleventy website
Start by creating a file in our src directory called sitemap.njk.
You might be wondering but I thought it would be an XML file? - And you are right. We can, however, do this by adjusting the permalink as such:
---
permalink: '/sitemap.xml'
---
All right, this will already create a file called sitemap.xml. Now let’s add all the pages we want to be found and crawled.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
{% for page in collections.all %}
<url>
<loc>{{ page.url | url }}</loc>
<lastmod>{{ page.date.toISOString() }}</lastmod>
</url>
{% endfor %}
</urlset>
This will give us the following result:
<?xml version="1.0" encoding="utf-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>/posts/article-1/</loc>
<lastmod>2020-07-12T03:00:00.000Z</lastmod>
</url>
<url>
<loc>/posts/article-2/</loc>
<lastmod>2020-08-12T03:00:00.000Z</lastmod>
</url>
<!-- more -->
<url>
<loc>/sitemap.xml</loc>
<lastmod>2021-01-24T11:59:09.087Z</lastmod>
</url>
</urlset>
Pretty cool. As you can see, we are missing the full URL, though. And at the bottom, we can even see the sitemap itself in the list.
We don’t want that, so let’s exclude the sitemap from being entered.
---
permalink: /sitemap.xml
eleventyExcludeFromCollections: true
---
This will ensure this page is not mentioned in any collection so that it won’t show up in our sitemap.
Then we need to look into adding the full URL.
A good practice is to create a site-wide variable in that we can store certain variables, like our full website URL.
Let’s create a file called site.json inside our src/_data folder.
{
"name": "The Todoist",
"url": "https://thetodoist.com"
}
You can extend the information in there as much as you like. We can use the variables in the following manner:
{{ site.url }}
So let’s add that to our sitemap.
---
permalink: /sitemap.xml
eleventyExcludeFromCollections: true
---
<?xml version="1.0" encoding="utf-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
{% for page in collections.all %}
<url>
<loc>{{ site.url }}{{ page.url | url }}</loc>
<lastmod>{{ page.date.toISOString() }}</lastmod>
</url>
{% endfor %}
</urlset>
That’s it. We now get the desired sitemap output!
Adding a robots.txt file in Eleventy
Another good SEO addition is the robots.txt file. This file is generally read first by crawlers and describes rules as to which pages the crawler may visit for crawling or not.
In there, we can also note the sitemap location.
Create a robots.njk file inside the src directory.
---
permalink: '/robots.txt'
eleventyExcludeFromCollections: true
---
User-agent: * Allow: / Sitemap: {{ site.url }}/sitemap.xml
Here we state that the file should be called robots.txt and excluded from the sitemap.
Then we place the robots’ content; in this case, we allow all robots on all paths.
In the last line, we give the crawler the path to the sitemap.
The output looks like this:
User-agent: *
Allow: /
Sitemap: https://thetodoist.com/sitemap.xml
And this is how you create a sitemap for an Eleventy blog. You’ll then want to submit the sitemap in Google Search Console. After the indexation, perform an internet search and see if you can find your pages in the search results!
If you follow the series, you can find the full code in this GitHub repo.
Thank you for reading, and let’s connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on Facebook or Twitter